The End of Code as the Bottleneck








Early Days of AI Code Generation
At Podium, like most engineering teams, the SDLC was built around a single constraint: engineering capacity. That assumption shaped everything from prioritization and planning to PRDs, sprints, tickets, CI, and so on. Every process and system was aggressively optimized to maximize around the scarcest resource: generating code.
When AI tools first showed up, they largely reinforced that model. In late 2023 and early 2024, we leaned heavily into tools like Copilot and saw around a 30% increase in output for many engineers.*
This was super meaningful – 30% more potential value delivered to customers! So, we encouraged a lot of experimentation. If a new AI codegen tool got mentioned on the internet in 2024, you could bet someone on our team was using it.
But while writing code got faster, the change was still incremental. We experimented with other AI point-solutions for code review, testing, and more, but on their own they had limited impact. The overall SDLC from ideation to shipping stayed largely the same.
The Beginnings of Real Change
In mid-2024, some of our engineers started using Cursor. What we noticed was that they weren’t just producing more code more quickly, these engineers were changing their approach to engineering using AI. More time went into shaping the problem and planning, and less into typing out code. Work shifted into larger, more complete chunks. Engineers started to think at the granularity of the customer problem, not the pull-request.
The result was another meaningful increase in engineering velocity when shipping features.
That’s when we decided this shift was non-optional. We rolled Cursor out across the engineering team, defined a set of best practices, and codified these in a shared cursor.md for each repo so the entire engineering organization could use the tool consistently. And we made it very clear to everyone that becoming great at using AI to code was now a core part of their job.
The result was a 250% increase in code output over the next 12 months.
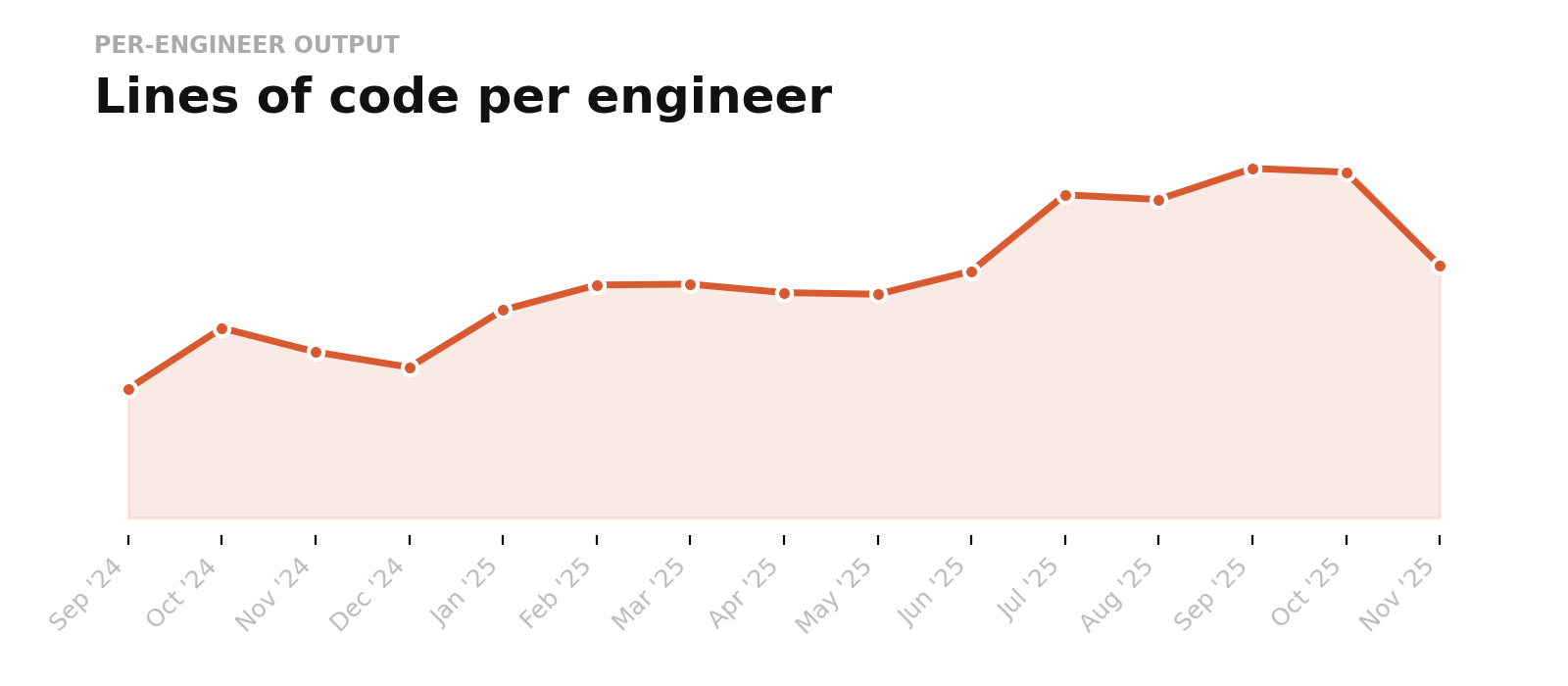
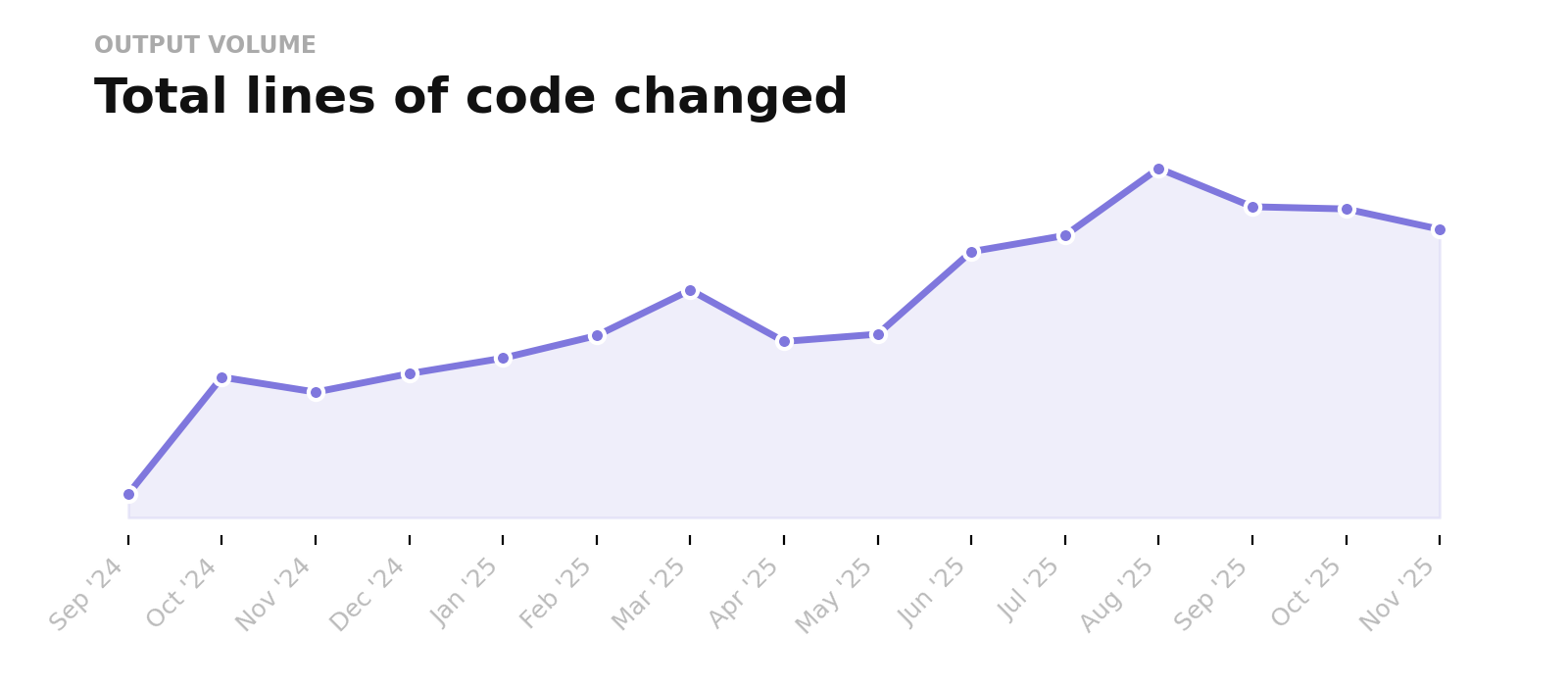
† we intentionally chose these metrics while knowing they are not perfect
This was one of our earliest and most important lessons: once we standardized how these tools were used, the impact became much more apparent and consistent across teams. Experimentation was fine, but real transformation came from making effective patterns uniform across the org.
Still, we were largely operating in the same old SDLC model. We were shipping much more complex features much more quickly, but the process looked mostly the same throughout, from PRD to CI/CD.
November 2025: The Old Model Shatters
Two things locked into place in Q4 2025. First, the new models (most notably Opus 4.5) crossed some unseen threshold and began producing precise, well-structured code that looked much closer to what a senior engineer would write. Second, the coding tools (e.g. Claude Code) had also seemingly crossed a threshold and could keep the new models on-rails for far larger changes and iterate without human intervention.
Together, these marked a clear step change. AI Agents could now generate much better code, but just as importantly, they could generate that code much more autonomously by following multi-step instructions reliably, operating with far less supervision, and sometimes even being able to “one-shot” well-defined features. Features that used to take a week or more could now be generated in hours, and shipped in a single day.
Two things seemed obvious to us.
First, it was inevitable that developers would spend much less time hand-writing code, but would generate a lot more code than ever before. Instead of focusing on code, engineers would need to orchestrate, review, and guide these systems that could suddenly execute complex development tasks on their own.
Second, it was clear that we would suddenly have a completely different set of bottlenecks in our SDLC than we had before. Code used to be the scarcest resource and writing it used to occupy 80%+ of shipping time. We saw a world where code generation would occupy less than 10% of shipping time. Review, testing, validation, CI, and even product definition were about to become much bigger bottlenecks than generating code.
Shifting Our Mindset
We realized we needed to stop asking “How do we help engineers write code faster?” and start asking “How do we redesign the system around new constraints?”. We needed to rethink our entire software development lifecycle from first principles.
That meant two things;
First, we had already learned that standardization and mandatory adoption were essential. So, in January, we put together an internal plan that focused on a new set of shared patterns, structured exploration, training, and a near-term AI-powered SDLC baseline. This involved standardizing Skills, Plans, Subagents, and more – the new primitives for AI development. The overall message to our engineers was: “Agents write code, you supervise them.”
Second, we needed to address the new bottlenecks immediately. Our first focus would be the bottom of the funnel: review, testing, CI, and the mechanical friction that slows down code that is already ready to ship (though we believe there are plenty of other new bottlenecks too).
So we began building a whole bunch of tools and AI-powered workflows to support an AI-native SDLC where PRs can converge faster, infrastructure bottlenecks can be resolved automatically, and engineers can stay focused on the areas where judgment matters most. These tools will be the focus of our next few posts.
The result? Since January, we have increased our code output by an additional 3x and lowered cycle times* by 50%.
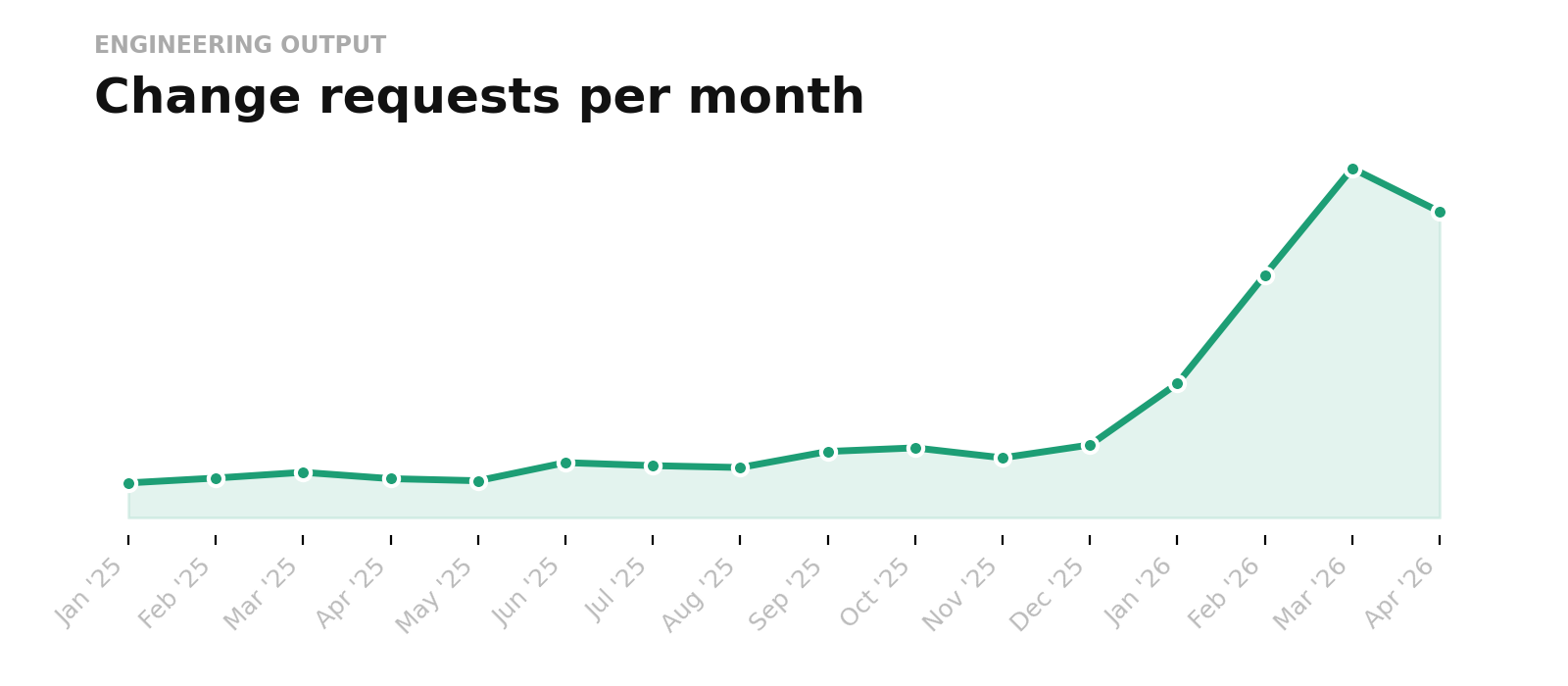
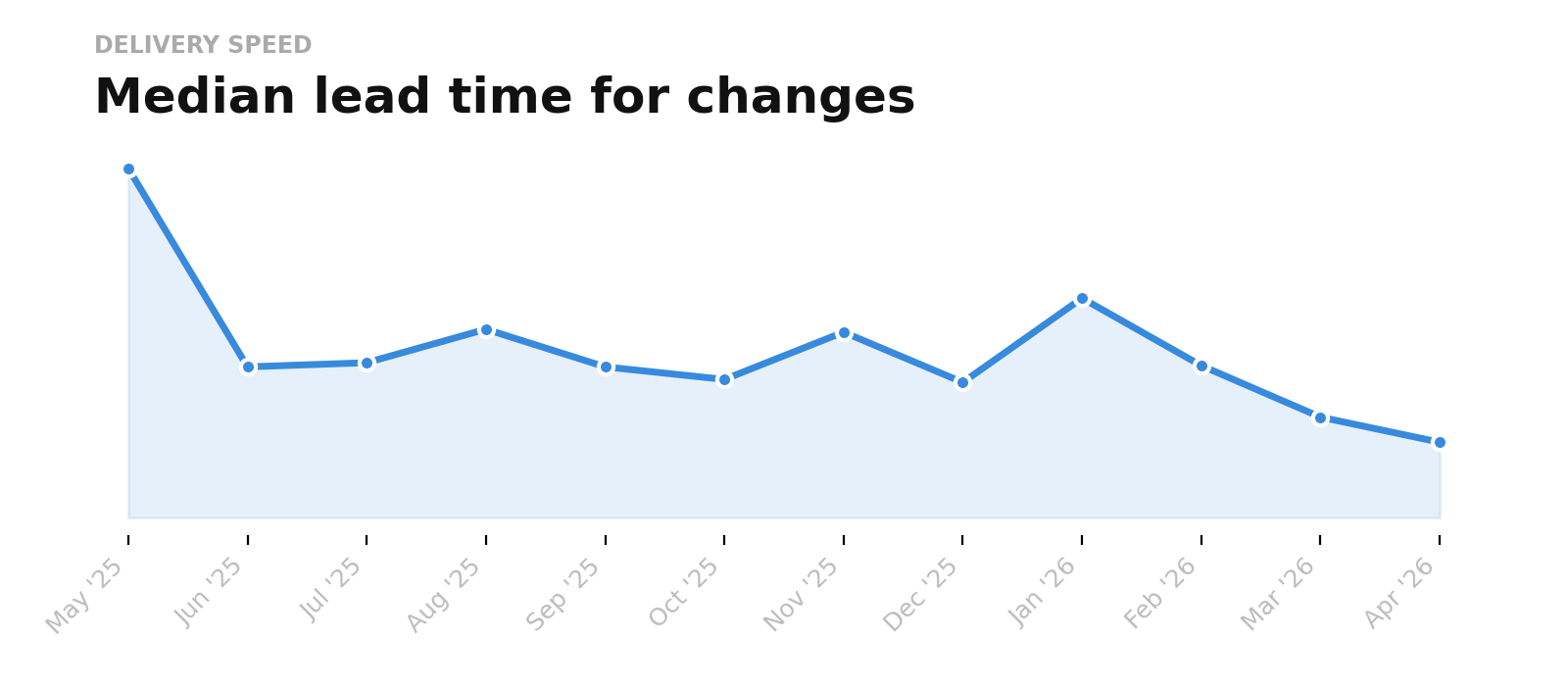
That wasn’t made possible by just a new model or a new tool. It has required a fundamental re-thinking of the entire SDLC. And this is the second essential lesson: to achieve all the gains we believe are possible, the entire SDLC must be rebuilt to be AI-native.
Combined with our earlier gains, we are now shipping about 10x more code than we were two years ago. And we feel like we’re just getting started.
In the next post, we will cover in detail where we felt the pressure of new bottlenecks first: the bottom of the funnel. As code output increased, review, testing, and CI could not keep up. We will break down what failed, what we changed, and how this led us to build a harness for AI-native software delivery.
†An Aside: Measuring Output
Any measurement is controversial – more code does not necessarily equal functionality or quality or customer value.
But, to know we’re making progress, we need to measure something. So we’ve chosen three output metrics: lines-of-code per engineer-week (LOC Pew), merge-requests per engineer-week (MR Pew), and merge-request cycle time (how long it takes an MR to go from submitted to deployed). Whenever we tout an “N% increase in output,” we mean that at least one of LOC Pew or MR Pew increased by that much, and usually both.